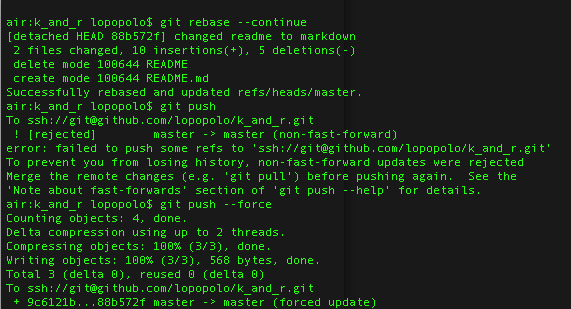
And proof that this setup is both good and bad – CI failed because I forgot to set the publish timestamp in the post YAML on the previous post. But CI ALSO failed because I forgot to run gazelle. #win #fail #bazel #hypstatic
permalinkhyperbola :: lifestream
I took a hacksaw to my homebrew installation. I'm not sure how this happened but the brewfile I've been carrying around at one point had the entire dependency graph in it rather than the explicitly installed deps ... which made everything on my new Mac an explicitly installed dep. I had hundreds of libs installed for no reason. Burned everything down and started from scratch. #fail #win github.com/lopopolo/dotfiles/blob/fb9af6bd19df2149dba5a63a8db161702bcbe5db/homebrew-packages/Brewfile.rooster
permalinkyikes and pagintated navigation for archive pages had month and year mixed up in the link. #hypstatic #fail
permalinkooof. While hacking on the lifestream part of the static site generator, uncovered that previous and next buttons for traversing lifestream permalinks had their polarity swapped. That bug has been there for over a year. #hypstatic #fail
permalinkDependency management in Python makes me sad. #fail #python #hypstatic
permalinkI've lost my ability to develop locally since I don't want to install VirtualBox on my new laptop. #fail #hypstatic
permalinkI run an outdated version of Django. #django #fail #hypstatic
permalinkThe terraform config for this project is on 0.12 and I have no desire to update it to 0.13. #fail #terraform #automation #hypstatic
permalink#vscode and LLDB in VSCode were SO amazing to use. Within a couple of iterations, I was able to track down the use-after-free: github.com/artichoke/artichoke/pull/674 #fail #win #artichoke
permalinkAfter 50 PRs, I was able to put GH-442 to bed and remove the Rc wrapper from the Artichoke state github.com/artichoke/artichoke/pull/670 #win This refactor took 4 months #fail #rust #artichoke
permalinkNothing like a little build breakage to start the weekend github.com/artichoke/artichoke/pull/417 #artichoke #fail
permalinkReported a critical bug in rustfmt #fail #github #patch github.com/rust-lang/rustfmt/issues/3770
permalinkAlso added many more converter implementations with macros. There are 988 TryConvert implementations. #win #fail #artichoke
permalinkLed to reporting this #mruby bug: github.com/mruby/mruby/issues/4684 #github #fail although I was able to work around it #artichoke
permalink
The converters are central to #artichoke. Changing this core abstraction was painful: 84 files changed, 2000 lines added, 2800 lines removed. #fail #git
permalinkThis was a nasty PR github.com/artichoke/artichoke/pull/242 #artichoke #fail
permalinkI'm trying to improve Regexp performance in #artichoke by using the regex crate instead of oniguruma in some cases. It turns out not to be faster in all cases #patch #rust #fail github.com/rust-lang/regex/issues/604
permalinkNeither mruby-sys nor onig can build with wasm-unknown-unknown or wasm-wasi, so I was stuck with wasm-unknown-emscripten. The linker on mruby-sys would dead code eliminate artichoke_backend::Artichoke #fail #Wasm #artichoke #mruby
permalinkWith renewed focus of building my own #Ruby instead of extending #mruby, I put in some effort to make mruby an implementation detail of #artichoke. Lots of refactoring with sed. #fail
permalinkCactusRef is still an incredibly unsafe crate, but at least it aborts if it detects a use-after-free #fail #artichoke
permalinkThat memory leak turned out to be quite the yak shave. setjmp/longjmp from C leaving #rust memory in inconsistent state #fail github.com/artichoke/ferrocarril/pull/168
permalink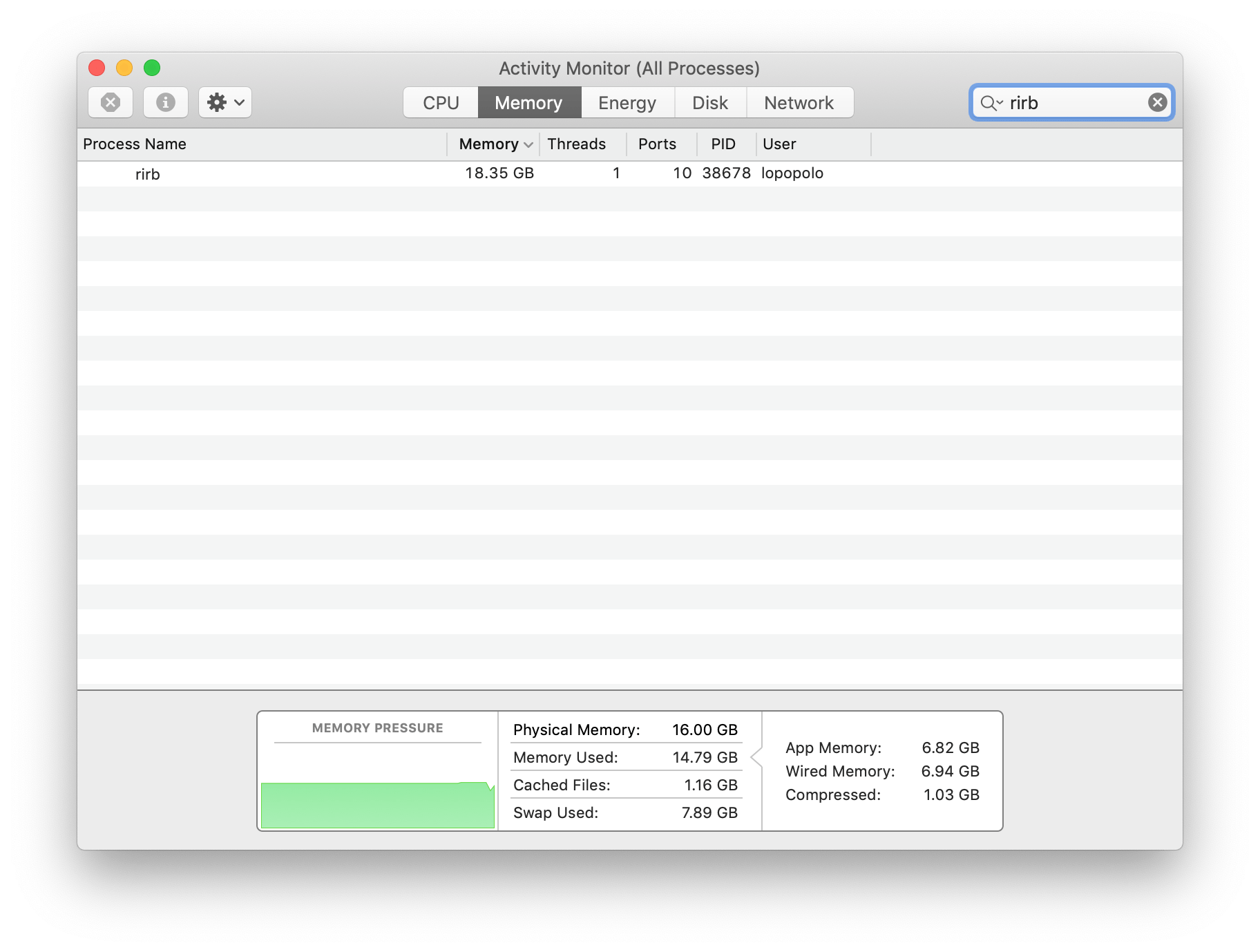
here's another Clippy bug #rust #fail github.com/rust-lang/rust-clippy/issues/4143
permalinkI found an ICE (internal compiler error) in clippy in #rust nightly #fail github.com/rust-lang/rust/issues/60067
permalinklooks like I didn't finalize the deploy in January so I had a few extra AMIs kicking around that I was needlessly paying for #aws #cost #fail #automation
permalink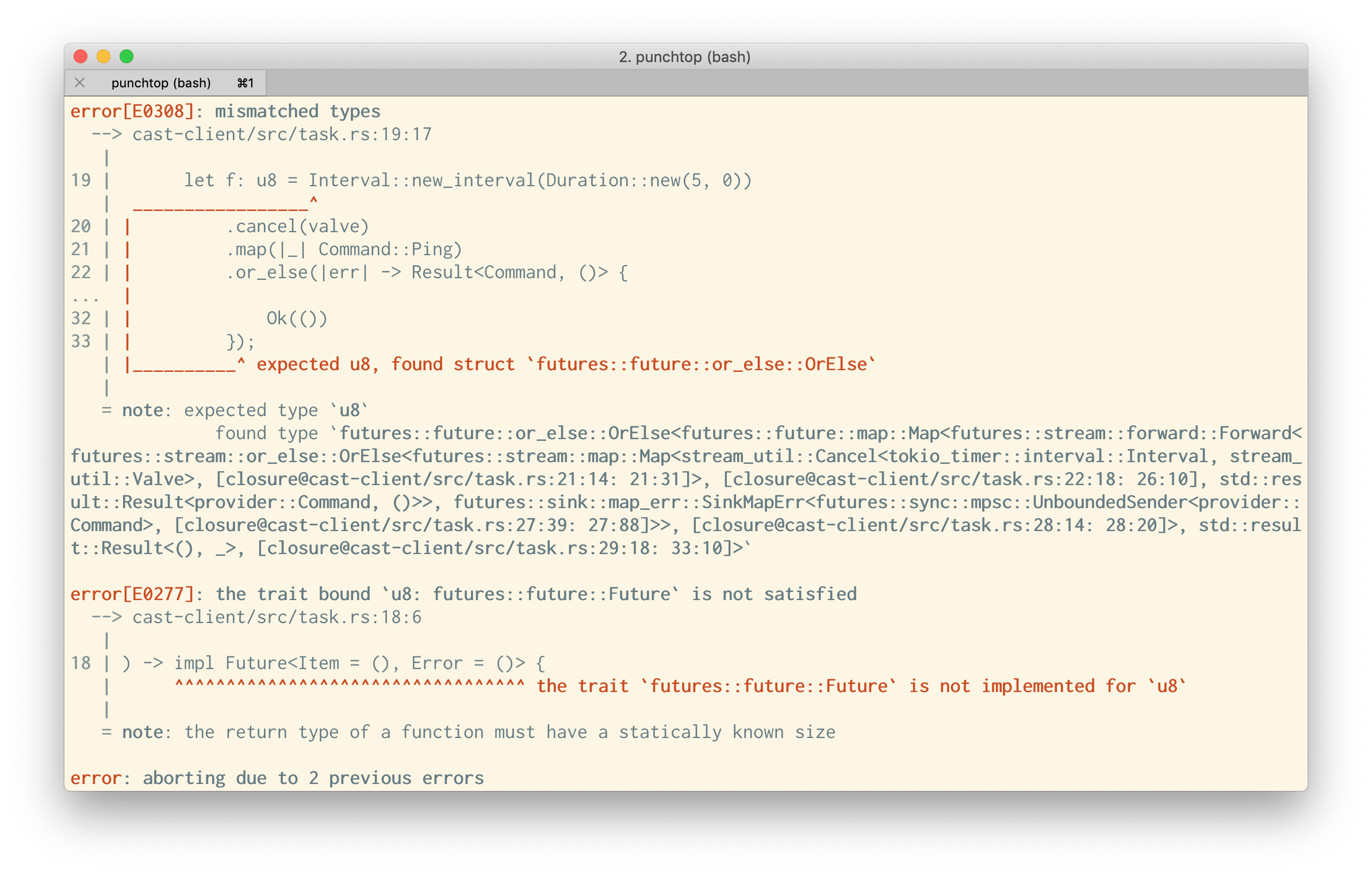
I was hard down for ~5min last night while rolling out secrets in parameter store. 0.149.0, 0.149.1, 0.149.2, and 0.149.3 were bad releases #fail. 0.149.4 is stable: github.com/hyperbola/hyperbola/compare/v0.148.0...v0.149.4. Postmortem pending.
permalinkAdd in some manual #terraform state edits and deleting things in the #aws console and we're recovered #fail #win
permalinkGot into an undeployable state due to differences in #provisioning between local and prod environments #fail github.com/hyperbola/hyperbola/commit/a914992
permalinkSo it turns out I shouldn't have ignored that MySQL backtrace when printing the help text of my new django management command in dev. That's why it hung when building the AMI. #fail One line fix: github.com/hyperbola/hyperbola/commit/728f1d68
permalinkwelp that didn't last long. CloudFlare only queries a subset of NS records to check for liveness and has determined that I no longer use CloudFlare. Working on purging them from #terraform and registrar now #fail
permalink#history throwback to the time that my wiki was spammed by a bot that turned all the pages into link spam for discount pharmaceuticals github.com/hyperbola/hyperbola/commit/1a3725b84bf82982945f68d14ff09ae7aa00d0ba #fail
permalink#terraform is now a package manager. Great. #fail. For some reason plugin downloads hang if the download gets an IPV6 edge node in their CDN.
permalinkDiscovered I had duplicate stanzas in my tfvars file. Removed the extraneous one. Broke EVERYTHING. #fail The worst was my admin IAM account losing access in the midst of a terraform apply. destroyed module.network, module.iam, and module.hyperbola-wiki
permalinkMedia backups have been failing since I moved the site to the new server. I've been uploading empty, corrupted tarballs. #fail fix here: github.com/hyperbola/hyperbola/commit/859128 Thank you gitlab & national check your backups day
permalinkmucking around in settings.py I ended up doing a top-level import from debug_toolbar. Yay for staging. #fail github.com/hyperbola/hyperbola/commit/26c4e1d
permalinksudo lsof | grep libssl | cut -d" " -f1 | sort | uniq -c | sort -rn #fail mta.openssl.org/pipermail/openssl-announce/2015-March/000020.html
permalink
Just added CORS headers for web-fonts on my 2 assets domains through cloudflare ... whoa. This has apparently been broken for a while #fail #win #hyperbola
permalinkgot another big #performance win by not minifying HTML in python not doing so shaved ~100ms off response time which means my server was spending more than 100ms of CPU time for the pleasure #fail
permalinkabout ~20% of server time for lifestream is spent reversing URLs for hashtags :/ #performance #fail
permalinkhowfuckedismydatabase.com hehe database problems. #fail #scale
permalink
Just updated the firmware on my Air. First two reboots = #kernelpanic. 3rd reboot = no mouse or keyboard. 4th reboot, everything works? #fail
permalink
#versioncontrol, or the lack thereof. This was my first major software project. I was a junior in high school. I was making a symbolic math thing. #fail or the reasons any CS class should teach #git
permalink#notetoself: Next time you need to run more than 3 tasks that take 10 minutes or more to run, invest in figuring out how to script it #fail #thesis2012
permalink#lessonlearned: Don't create a billion Timer objects. One is probably enough. Managed to get #eclipse to fail at repainting itself because it was running about 700 threads #java #fail
permalinkI do not care whether your API is RESTful. Does it work and will it do what I want? #marketing #fail
permalinkall your heapspace are belong to me! #java #outofmemory #fail
permalinkgithub.com/lopopolo/dotfiles/blob/master/scripts/cron-update-remotes.bash All of my problems with this script had to do with adding passphrases to my #ssh keys #fail
permalinkjust discovered that once you're in cmd+TAB mode on OS X, cmd+` cycles backward. So much easier than cmd+shift+TAB #learnability? #fail #win
permalink
Cute ad on stackoverflow. It reads "<heart> Your Job" #adtargeted (apparently my db doesn't like unicode #fail)
permalinksweet, there's been a patch since may, but no need to put out a bugfix release or anything github.com/github/gollum/issues/147 #fail #git
permalink#backintheday, before I understood how the relational part of MySQL worked, I made 20 columns to hold metadata about a record. 20 columns wasn't enough. Foreign keys #ftw. learning #fail
permalink#compiling #gcc from source to get an ELF cross-compiler on OSX. This is so #fail
permalinkBecause kernel.org is down, I used airdrop to copy over a cached version of the git source and formula from another computer so I could install it with homebrew #fail
permalinkfor the number of times i ssh'd into my iMac this sumer, you would think that I'd have just put my ssh key on it #fail #doingitthehardway
permalink